TensorFlowを使用して画像判定を行ってみました。TA11 画像分類 検討はバイナリ判定ですが、こちらはクラス判定をしてみます。
(なんとなくの設定が多いです。またデータもかなり簡易なものです。)
二値判定と違い、分類分けができるので、フォルダの中を任意の種類に振り分けるなど、身近な作業の手伝いが期待できます。(画像が必要ですが)
ベース
対象: A110 例題A 片持ち梁の解析、A112 両持ち梁 曲げ (TA11)に
流体に関する解析の画像群を追加します。
解析結果をParaviewで表示したものについて分類します。
画像が片持ち梁の解析、両持ち梁または流体のものかを判定します。
学習データ:FreeCAD,ParaViewで取得した画像データ
学習モデル作成: TensorFlow 2.8.0 (Scikit-learnの関数を使用)
深層学習ライブラリ: keras 2.8.0
判定対象データ:Paraviewによるコンタ図
条件:
TA11のデータに以下を追加します。
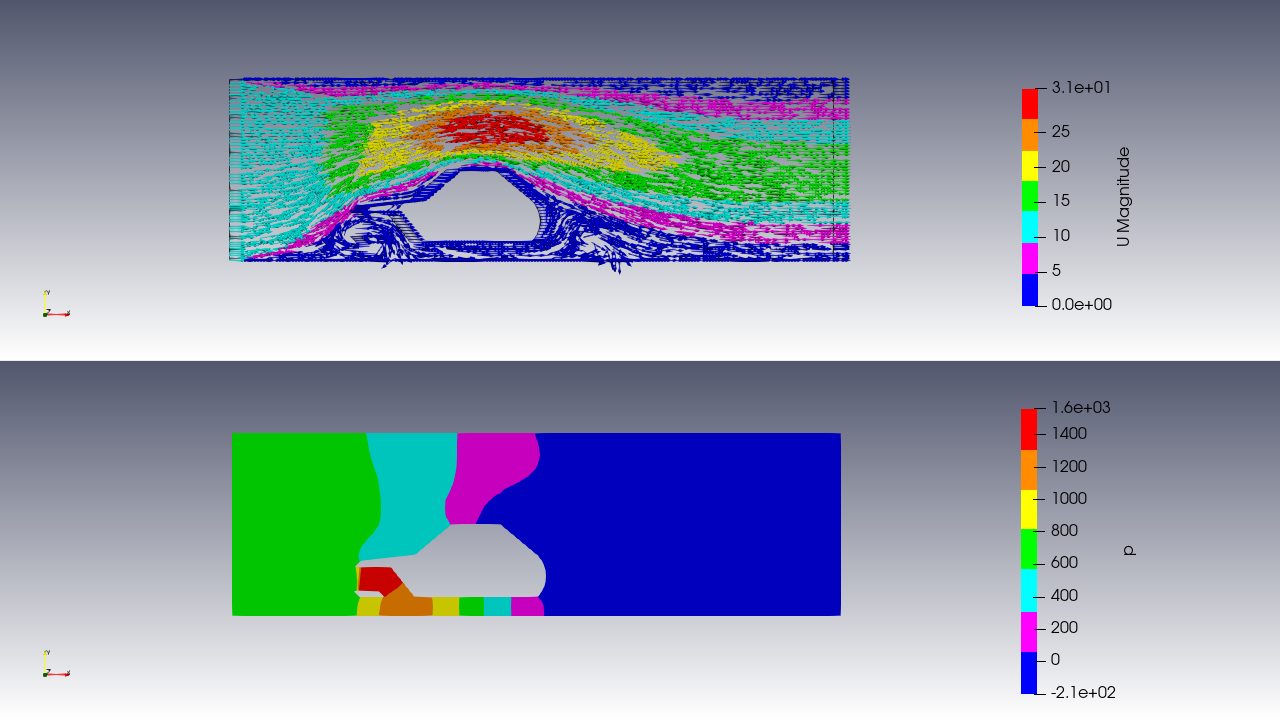
上記の解析結果図を判定させます。

教師データ:本サイトで行った幾つかの解析図を複製等(反転、回転)して用意しました。
TA11はプログラム内で複製していましたが、ドキュメントとして追加しました。
結果
| 片持ち Cantilever.jpg | 両持ち Double_sided.jpg | 片持ち2 Cantilever4.jpg | 両持ち2 Double_sided4.jpg | 流体結果 TA12_check_F2.png |
|---|---|---|---|---|
 | 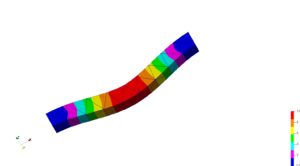 | 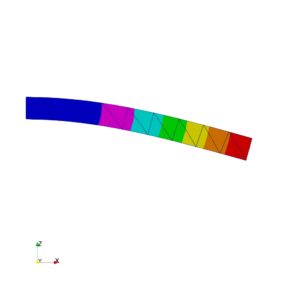 |  | |
| 持ち 判定〇 | 両持ち 判定〇 | 片持ち 判定〇 | 両持ち 判定〇 | 流体 判定〇 |
結果だけ確認したところ、判定できていました。

設定
| 項目 | 設定内容 |
|---|---|
| 学習データ数 | 片持ち320枚 両持ち480枚 流体225枚 |
| 仮想データ | - |
| バッチサイズ | 5 |
| エポック数 | 50 |
作業
モデル作成用ファイルをpythonで実行して、学習モデル(json/hdf5ファイル)を作成します。
モデルに検証用ファイルを読ませて判定します。
フォルダ構造
TA12_r0 ├ Cantilever2 //学習画像データ 片持ち320枚 │ ├ 11.jpg │ ├ ~ │ └ res_solid-1.png ├ Double_sided2 //学習画像データ 両持ち480枚 │ ├ 22.bmp │ ├ ~ │ └ WS000013.png ├ fluid //学習画像データ 両持ち225枚 │ ├ B201_buildings2.png │ ├ ~ │ └ T721_032_buoBouSim_hotRoom.png ├ judge //判定用画像データ │ ├ Cantilever.jpg │ ├ Cantilever4.jpg │ ├ Double_sided.jpg │ ├ Double_sided4.jpg │ └ TA12_check_F2.png ├ LearnModel //学習モデル │ ├ leanGraph.png │ ├ learnHis.json │ ├ model.json │ └ weightData.hdf5 ├ TA12_Learn_r2.py //モデル作成用ファイル : 学習モデルを作成します。 └ TA12_judge_r2.py //評価用ファイル : 判定用画像データを判定します。
サンプルファイル:TA12_r1.zip (79MB)
実行ファイル
モデル作成用ファイル:TA12_Learn_r2.py
# -*- coding: utf-8 -*-
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from keras.optimizers import RMSprop
from keras.preprocessing.image import img_to_array, load_img
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import os
import pickle
import glob
#------------------------
#パラメータ
#------------------------
#ファイルフォルダ
fileDir = os.path.dirname(__file__)
# ルートパス
rootPathTRAIN = fileDir +"\\"
# 作成物フォルダ
res_PATH = rootPathTRAIN + "LearnModel\\"
#データ区分け 参照フォルダ
Part = ["Cantilever2","Double_sided2","fluid"]
num_Part = len(Part)
# 入力画像のパラメータ
pic_width = 32 # 入力画像の幅
pic_height = 32 # 入力画像の高さ
pic_ch = 3 # 3ch画像(RGB)で学習
pic_size = 64
#作成データ
makeModel = "model.json"
weightData = "weightData.hdf5"
learnHis = "learnHis.json"
leanGraph = "leanGraph.png"
#学習パラメータ
batchSize = 5 # バッチサイズ
numClasses = num_Part # クラス数
epochs = 50 # エポック数
dropoutRate = 0.2 # 過学習防止にデータ20%を削除
nomalize1 = 255.0
#学習確認グラフ
graphSize = 12
graphHeigt = 10
graphFont = 25
#データの格納
# catNum = 0
# imgCount = 0
# picData =[]
def plotHIS(history,
checkGraphPath,
picSizeWidth,
piSsizeHeight,
fontSize):
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.figure(figsize=(picSizeWidth, piSsizeHeight))
plt.rcParams['font.family'] = 'Times New Roman'
plt.rcParams['font.size'] = fontSize
plt.plot(epochs, acc, color = "blue", linestyle = "solid", label = 'train acc')
plt.plot(epochs, val_acc, color = "green", linestyle = "solid", label= 'valid acc')
plt.plot(epochs, loss, color = "red", linestyle = "solid" ,label = 'train loss')
plt.plot(epochs, val_loss, color = "orange", linestyle = "solid" , label= 'valid loss')
plt.legend()
plt.grid()
plt.savefig(checkGraphPath)
plt.close()
def main():
data_x = []
data_y = []
data_x_pic = []
data_y_pic = []
numClasses = num_Part
for index, cateP in enumerate(Part):
photos_dir = rootPathTRAIN + cateP
files = glob.glob(photos_dir + "/*")
#-----------------------------------------------------
for i,filepath in enumerate(files):
# for filepath in imgDaras(rootPathTRAIN +"" +cateP):
img = img_to_array(load_img(filepath, target_size=(pic_width,pic_height, pic_ch)))
data_x.append(img)
data_y.append(index) # 教師データ(正解)
# #画像の書き出し
# imgCount = 0
# for datPic in picData:
# imgCount = imgCount + 1
# datPic.save(res_PATH +'lena_flip'+'_'+str(imgCount)+'.jpg', quality=95)
#-----------------------------------------------------
data_x = np.asarray(data_x) # NumPy配列
data_y = np.asarray(data_y) # NumPy配列
#学習用と検査用にデータを分割する
x_train, x_test, y_train, y_test = train_test_split(data_x, data_y, test_size=0.2)
x_train = x_train.astype('float')
x_test = x_test.astype('float')
x_train = x_train / nomalize1
x_test = x_test / nomalize1
# ラベルのコーディング
y_train = np_utils.to_categorical(y_train, numClasses)
y_test = np_utils.to_categorical(y_test, numClasses)
# データ個数
print(x_train.shape, 'x train samples')
print(x_test.shape, 'x test samples')
print(y_train.shape, 'y train samples')
print(y_test.shape, 'y test samples')
#モデル作成
model = Sequential()
#2次元畳み込み層
model.add(Conv2D(32,(3,3),
padding='same',
input_shape=x_train.shape[1:],
activation='relu'))
#2次元畳み込み層
model.add(Conv2D(32,(3,3),
padding='same',
activation='relu'))
#プーリング層
model.add(MaxPooling2D(pool_size=(2, 2)))
# ドロップアウト
model.add(Dropout(dropoutRate))
#2次元畳み込み層
model.add(Conv2D(64,(3,3),
padding='same',
activation='relu'))
#2次元畳み込み層
model.add(Conv2D(64,(3,3),
padding='same',
activation='relu'))
#プーリング層
model.add(MaxPooling2D(pool_size=(2, 2)))
# ドロップアウト
model.add(Dropout(dropoutRate))
#次元削減
model.add(Flatten())
# 全結合層
model.add(Dense(512, activation='relu'))
# ドロップアウト
model.add(Dropout(dropoutRate))
# 全結合層
model.add(Dense(numClasses, activation='softmax')) # 活性化関数:softmax
# モデル表示
#model.summary()
# コンパイル
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=0.0), metrics=['accuracy'])
#モデルの学習 データの10%を使用して検証
history = model.fit(x_train,
y_train,
batch_size=batchSize,
epochs=epochs,
# verbose=1,
validation_split=0.1)
# テスト用データで確認
check = model.evaluate(x_test,
y_test,
verbose=0
)
# 損失値確認
print('check loss:', check[0])
# 正解率
print('check accuracy:', check[1])
# 学習過程をグラフ
plotHIS(history,
checkGraphPath = res_PATH + leanGraph,
picSizeWidth = graphSize,
piSsizeHeight = graphHeigt,
fontSize = graphFont)
#構造セーブ
open(res_PATH + makeModel,"w").write(model.to_json())
#学習の重み保存
model.save_weights(res_PATH + weightData)
#履歴保存
with open(res_PATH + learnHis, 'wb') as f:
pickle.dump(history.history, f)
if __name__ == '__main__':
#ファイル削除
if(os.path.isfile(res_PATH + leanGraph)):
os.remove(res_PATH + leanGraph)
if(os.path.isfile(res_PATH + makeModel)):
os.remove(res_PATH + makeModel)
if(os.path.isfile(res_PATH + weightData)):
os.remove(res_PATH + weightData)
if(os.path.isfile(res_PATH + learnHis)):
os.remove(res_PATH + learnHis)
main()TA12_judge_r2.py
# -*- coding: utf-8 -*-
import numpy as np
from keras.models import model_from_json
from keras.preprocessing.image import load_img, img_to_array
import glob
import os
#------------------------
#パラメータ
#------------------------
# ラベル
labels =['片持ち梁', '両持ち梁', '流体']
#ファイルフォルダ
fileDir = os.path.dirname(__file__)
# ルートパス
rootPathTRAIN = fileDir +"\\"
#学習データ保存フォルダ
lernPath = rootPathTRAIN + "LearnModel\\"
#検査するファイル
checkFile = rootPathTRAIN + "judge\\"
#評価対象ファイル
files_list=[]
path = rootPathTRAIN + "judge\\"
files = glob.glob(path + "/*")
for f in files:
files_list.append(os.path.basename(f))
#作成データ
makeModel = "model.json"
weightData = "weightData.hdf5"
# 画像情報
picWidth = 32
picHeight = 32
colorCh = 3
nomalize1 = 255.0
#-------------------処理----------------------------
#モデルの読み込み
model = model_from_json(open(lernPath + makeModel).read())
#重みを読み込み
model.load_weights(lernPath + weightData)
count=0
for i in files_list:
img = load_img(checkFile + i, target_size=(picWidth, picHeight))
img = img_to_array(img)
img = img.astype('float')/nomalize1
img = np.array([img])
# データ予測実行
y_pred = model.predict(img)
# 要素番号確定
number_pred = np.argmax(y_pred)
# 予測表示
print("#---------------")
print("ファイル名" +i)
print("index:", number_pred) # ラベル番号
print('[判定]:', labels[int(number_pred)]) # 予想ラベル
print("predict:", y_pred) # 出力値追加
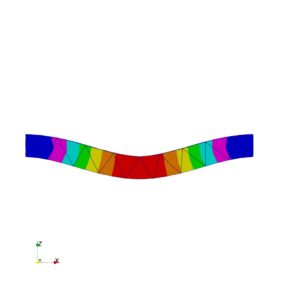
試しに、ビームに見えるような流体の解析図を行ってみました。
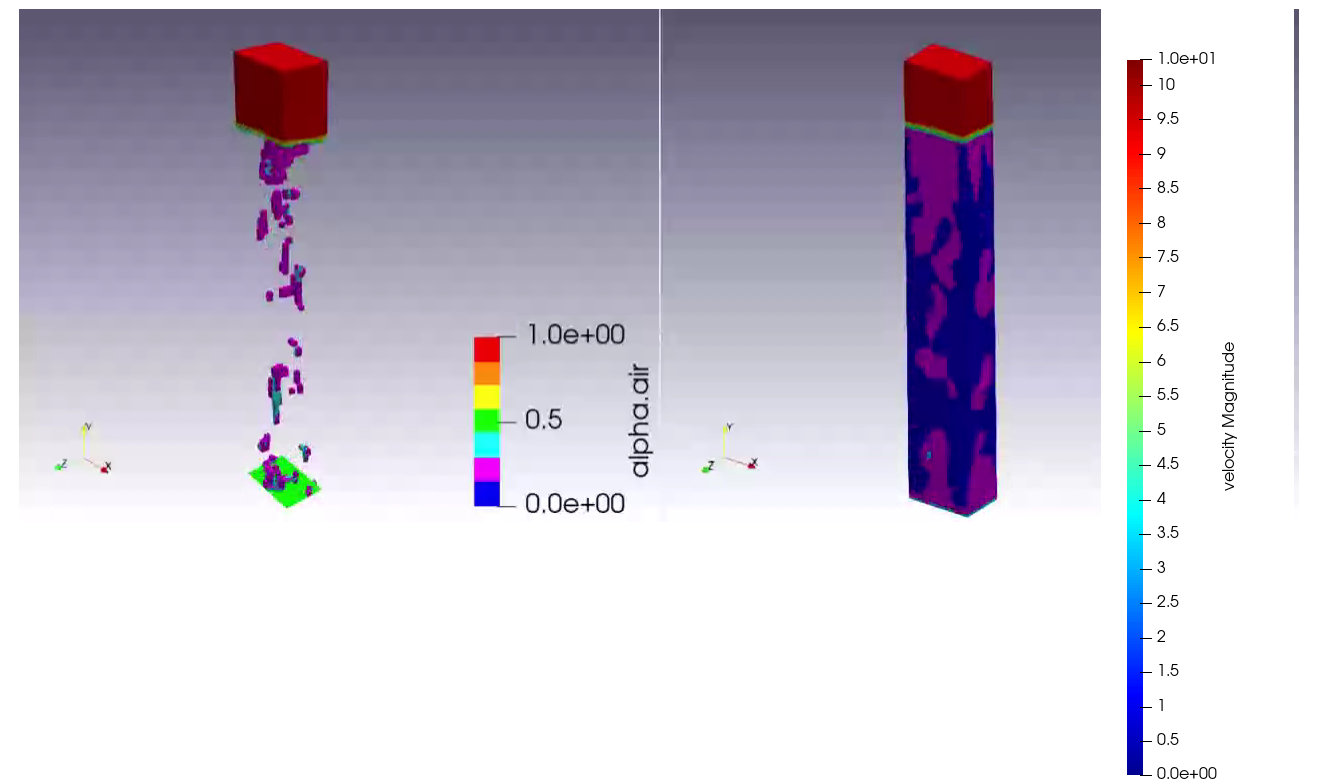

この図の場合だと判断がつかないようです。片持ち梁の判定になりました。

精度を上げるには手間が必要のようです。(学習が甘い部分もあります)
コメント