TensorFlowを使用して画像判定を行ってみました。
(なんとなくの設定が多いです。またデータもかなり簡易なものです。)
対象: A110 例題A 片持ち梁の解析、A112 両持ち梁 曲げ 左記相当の梁曲げ結果図
FreeCADで実施した解析(ccx)をParaviewで表示したものを分類します。
画像が片持ち梁の解析のものか、両持ち梁のものかを判定します。
学習データ:FreeCAD,ParaViewで取得した画像データ
学習モデル作成: TensorFlow 2.8.0
深層学習ライブラリ: keras 2.8.0
判定対象データ:Paraviewによるコンタ図(変位)
条件:
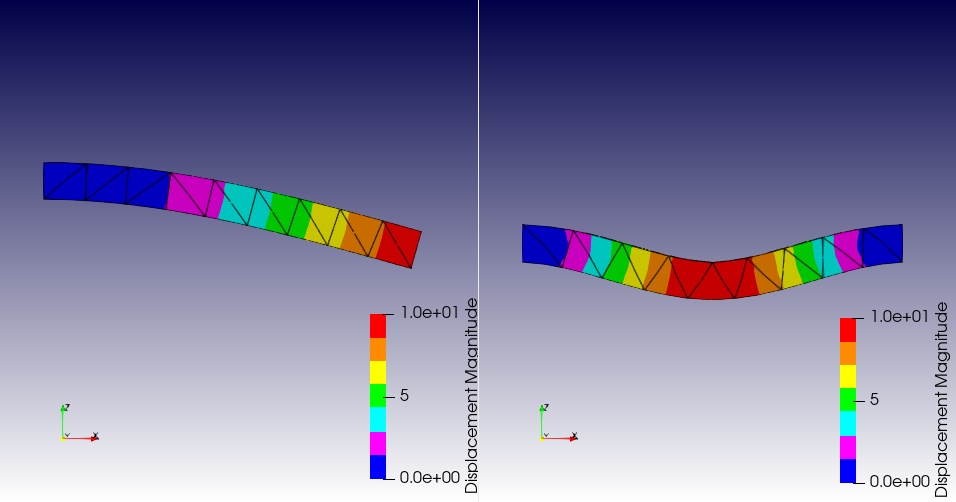
上記の解析結果図を判定させます。
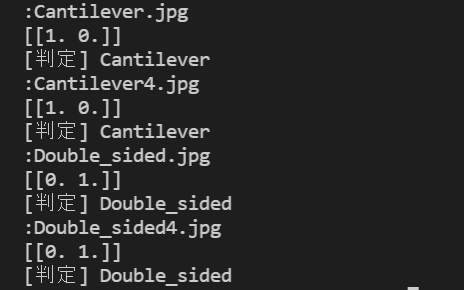
結果
| 片持ち Cantilever.jpg |
両持ち Double_sided.jpg |
片持ち2 Cantilever4.jpg |
両持ち2 Double_sided4.jpg |
|---|---|---|---|
 |
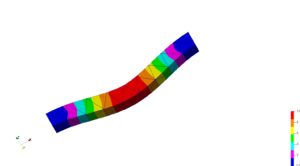 |
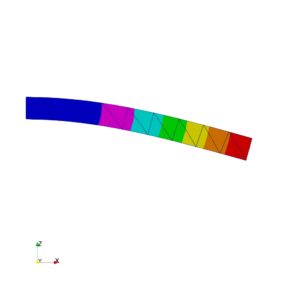 |
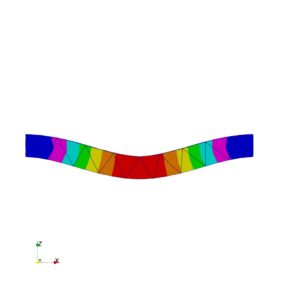 |
| 片持ち 判定〇 | 両持ち 判定〇 | 片持ち 判定〇 | 両持ち 判定〇 |
結果だけ確認したところ、判定できていました。
設定
| 項目 | 設定内容 |
|---|---|
| 学習データ数 | 片持ち20枚 両持ち20枚 |
| 仮想データ | 40枚を2160枚に拡張 |
| バッチサイズ | 10 |
| エポック数 |
50(50前に停止) |
作業
モデル作成用ファイルをpythonで実行して、学習モデル(h5ファイル)を作成します。
モデルに検証用ファイルを読ませて判定します。
フォルダ構造
TA11_V4_data ├ Cantilever2 //学習画像データ 片持ち20枚 │ ├ 11.jpg │ ├ ~ │ └ res_solid-1.png ├ Double_sided2 //学習画像データ 両持ち20枚 │ ├ 102.bmp │ ├ ~ │ └ WS000013.png ├ judge_beam //判定用画像データ │ ├ Cantilever.jpg │ ├ Cantilever4.jpg │ ├ Double_sided.jpg │ └ Double_sided4.jpg ├ model //学習モデル 作成された*.h5ファイル │ ├ beamtest_V4.h5 │ └ beamtest_V4.npy ├ beamtest_V4_training.log //計算ログ ├ TA11_V4.py //モデル作成用ファイル : *.h5ファイルを作成します。 └ TA11_V4_res.py //評価用ファイル : 判定用画像データを判定します。
サンプルファイル:TA11_V4_data_r1.zip (42MB)
実行ファイル
モデル作成用ファイル
#インポート
# import tensorflow
import keras
from PIL import Image
import glob
# import os
import numpy as np
# from PIL import ImageFile
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.utils import np_utils
#収束判定停止用
from keras.callbacks import EarlyStopping
#オプティマイザー
from tensorflow.keras.optimizers import RMSprop
# from tensorflow.keras.optimizers import SGD
# from tensorflow.keras.optimizers import Adam
#-------パラメータ-------
#>>>>>>>>
#データ区分け
folder = ["Cantilever2", "Double_sided2"]
#作成npy名
modelName = "beamtest_V4"
saveModel = "./model/" + modelName #h5ファイル
#>>>>>>>>
image_size = 64
loss = 'binary_crossentropy'
num_folder = len(folder)
batch_size = 10
epochs = 50
nomalize1 = 255.0
# EaelyStoppingの設定
stopFlag = 1
early_stopping = EarlyStopping(
monitor='loss',
min_delta=0.00001,
patience=4,
)
#計算ログ出力
# keras.callbacks.CSVLogger(filename, separator=',', append=False)
csv_logger = keras.callbacks.CSVLogger(modelName + '_training.log')
#------------------------
#宣言
X_train = []
X_test = []
y_train = []
y_test = []
#学習データ編集
for index, classlabel in enumerate(folder):
photos_dir = "./" + classlabel
files = glob.glob(photos_dir + "/*")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
#格納
X_test.append(data)
y_test.append(index)
#データ拡張 回転18step
for angle in range(0, 360, 20):
img_r = image.rotate(angle)
data = np.asarray(img_r)
X_train.append(data)
y_train.append(index)
#左右反転
img_trains = image.transpose(Image.FLIP_LEFT_RIGHT)
data = np.asarray(img_trains)
X_train.append(data)
y_train.append(index)
#上下反転
img_trains = image.transpose(Image.FLIP_TOP_BOTTOM)
data = np.asarray(img_trains)
X_train.append(data)
y_train.append(index)
#格納
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
xydata = (X_train, X_test, y_train, y_test)
np.save("./" + saveModel + ".npy" , xydata)
#------------------------
#データ読み込み
#------------------------
def load_data():
X_train, X_test, y_train, y_test = np.load("./" + saveModel + ".npy", allow_pickle=True)
# 0-1に正規化
X_train = X_train.astype("float") / nomalize1
X_test = X_test.astype("float") / nomalize1
y_train = np_utils.to_categorical(y_train, num_folder)
y_test = np_utils.to_categorical(y_test, num_folder)
return X_train, y_train, X_test, y_test
#------------------------
#学習の実施
#------------------------
def train(X, y, X_test, y_test):
model = Sequential([
Conv2D(32,(3,3), padding='valid',input_shape=X.shape[1:]),
Activation('relu'),
Conv2D(32,(3,3)),
Activation('relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.1),
Conv2D(64,(3,3), padding='valid'),
Activation('relu'),
Conv2D(64,(3,3)),
Activation('relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Flatten(),
Dense(512),
Activation('relu'),
Dropout(0.45),
Dense(2),
Activation('softmax')
])
# opt = RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=0.0)
model.compile(loss = loss,optimizer=RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=0.0),metrics=['accuracy'])
print(model.loss)
if stopFlag == 1:
model.fit(X, y, batch_size=batch_size, epochs=epochs, callbacks=[early_stopping,csv_logger]) # 途中停止
else:
model.fit(X, y, batch_size=batch_size, epochs=epochs, callbacks=[csv_logger])
model.save('./' + saveModel +'.h5') # HDF5ファイルにKerasのモデルを保存
# model.save('./'+ saveModel) #モデルセット作成
return model
#------------------------
#データ読み込みと学習の実施
#------------------------
def main():
# データの読み込み
X_train, y_train, X_test, y_test = load_data()
# モデルの学習
train(X_train, y_train, X_test, y_test)
main()TA11_V4_res.py
import cv2 as cv2
import numpy as np
import os
from keras.models import load_model
import glob
from PIL import Image
#-------パラメータ-------
#学習モデルの読み込み
saveModel = './model/' + "beamtest_V4.h5"
imgsize = (64, 64)
nomalize1 = 255.0
judgeStr = ["Cantilever", "Double_sided"]
#評価対象ファイル
files_list=[]
path = "./judge_beam/"
files = glob.glob(path + "/*")
for f in files:
files_list.append(os.path.basename(f))
#------------------------
model = load_model( saveModel)
#画像整理関数
def check_image(path):
img = Image.open(path)
img = img.convert('RGB')
img = img.resize(imgsize)
img = np.asarray(img)
img = img / nomalize1
return img
count=0
for i in files_list:
img = check_image(path+files_list[count])
print(":"+files_list[count])
print(model.predict(np.array([img]))) # 精度の表示
judeassy = np.argmax(model.predict(np.array([img])), axis=1)
if judeassy == 0:
print("[判定] " + judgeStr[0])
elif judeassy == 1:
print("[判定] "+ judgeStr[1])
count+=1追加
変位形状のない図でも行ってみました。
コンタカラーで判断することになると思います。
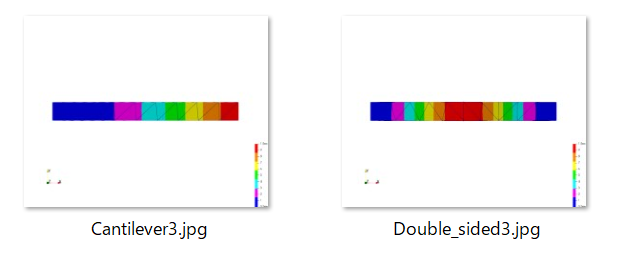
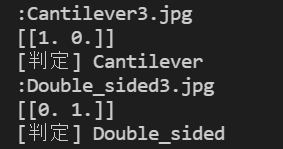
カラー傾向からか判定できていました。
コメント